
Product matching: The success factor in market intelligence
Big data is opening up new opportunities for retail to strengthen its market position. Using market intelligence, meaning an extensive knowledge of the market and the individual in-house position, companies are guarding themselves against a crowding out of the market and from the bitter price war. Amongst retailers, this approach requires a deep understanding of their products, prices, conditions and current market position.
Additionally, a modern IT infrastructure is called for which allows the use of an intelligent and self-learning big data analytics solution. Business advantages, after all, can only be achieved when the huge volumes of data involved can be meaningfully gathered and evaluated.
Driving factors in market intelligence
One decisive factor is the customer, whose requirements and habits have sharply altered over recent years. Comparison shopping through digitization, mobile shopping and price comparison portals has now developed into the norm. It is precisely in this area that companies in eCommerce need to delve into. Problems all too often arise with the assessment and recognition of market trends, as well as in keeping pace with existing and fresh competitors. But customers, above all, represent a challenge, since they extensively inform themselves online before purchase and are always just one click removed from other competitors.
Additionally, rapidly expanding data volumes are forcing online retail into introducing data-analysis platforms to obtain a transparent market overview. One example here is the use of big data for competitor and price observations: A meaningful benchmark can now no longer be attained with Excel tables and the like. Because of the diversity of product offerings today, this approach has long since lost any meaningfulness – and particularly so in the event where international competition is to be included. Market intelligence helps to identify similar or equivalent datasets with a heightened matching accuracy – this process is also termed ‘product matching’.
Generate added value internally and externally with product matching
Although data and customer analysis has long become routine in online retail, this often fails in the linking of data and in the creation of a transparent environment. Product matching is a form of data analysis in eCommerce of great importance both internally and externally.
Internally speaking, product matching is used in database cleansing: Duplicates are identified and eliminated in the product master-data of both online retailers and brand-name manufacturers. Two datasets representing the same product are considered a match here. Duplicates often arise due to differing product designations. These can emerge already when feeding data into the databank, since the product often carries inconsistent descriptions from the suppliers.
The worst-case scenario for a low-quality databank is that customer and product manager alike will be informed that a product is no longer available. The customer will then switch to a different provider and the manager wrongly reorder the item even though it is still in stock. By cleansing the databank and the resulting improvement in data quality, costs will be reduced, as well as usability and customer satisfaction boosted.
Product matching serves externally in both competitor and market monitoring. We speak of a match here when two datasets relate to comparable products. By introducing intelligent technologies, one’s own prices can be compared with the offerings in national and international competition, and solid analyses based upon this used to develop the pricing strategy of competitors. Retailers can then adjust their prices and product lines to the current market situation. This is the way that online operators are now readying themselves for the bitter price war and crowding out of the market by both pure players and startups.
Barriers to product matching
The biggest difficulties in the matching of product data lie in the handling of highly heterogenous product descriptions and a shortfall in standards for clear product identification (EAN/GTIN). In retail, there is virtually no requirement as to how a product description should look, what it should contain and how detailed it ought to be. Varying descriptions arise, among other things, from the use of:
- Domain-specific terms and abbreviations: In the fashion sector, for instance, the term “lg. A.” is an abbreviation for “long arm”. Over in the electronics field, however, LG is a brand-name manufacturer.
- Heterogenous designations for size and quantity entries, such as 168 items, as opposed to 3 times 56 items.
- Heterogenous notations of model designations, such as DHI655FX as opposed to DHI 655 FX or DHI-655 FX.
- Synonyms: In the fashion world, for example, a hoody, hoodie and hooded pullover all describe a pullover fitted with a hood.
In matching, the comparison of two products occurs by way of their attributes (size, color, brand etc.). In addition, the following similarity indicators are mostly called upon: Edit distance, Jaccard, tf-idf and trigram. To achieve a high-quality match, it is advisable to combine various measures for different attribute values (such as the “size” and “brand” attributes).
A further general challenge to matching is its effectiveness. To evaluate this, two individual measures are normally applied: Precision and recall.
Precision and recall determine effectiveness
The matching of products proves itself effective when a perfect balance between accuracy and hit ratio is attained – insiders in the IT sector speak here of recall and precision. In the ideal case, both of these values would reach 100 percent.
- Recall– the measure of completeness: Recall measures the proportion of recognized matches against all actual matches and thus serves as a gauge of matching completeness. If the recall is high, many of the actual existing matches were found.
- Precision– the measure of matching accuracy: It can be determined from matching accuracy how high the proportion of actual matches is against the recognized ones.
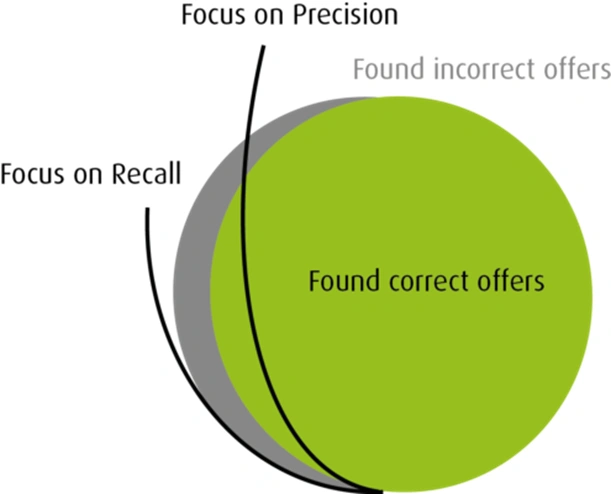
Figure 1: Recall vs. Precision.
Should the definition of a similar product be narrowly defined, the market analysis will then be less precise and a blind spot will result. The matching process, after all, will ignore similar products that have a varying description. Data quality relating to matching accuracy is very high in this scenario, but the measured values for recall correspondingly low.
A broader definition allowing for more variations would provide a better market overview, but the risk would increase here that dissimilar products will be mistakenly compared with one another. The rate of recall would be very strong here, yet the hit accuracy actually involved rather small.
Which advantages arise from market intelligence?
Companies in digital business attain through market intelligence a comprehensive transparency of the market situation and of their own processes. Product matching is an important component of this, since a strong data foundation is created from it, an error-free product management established and the basis for competitive comparison enabled.
Because customers can quickly obtain a good market overview using price comparison portals, companies are being forced to confront current market conditions: Amazon, for example, performs up to ten billion price alterations at peak selling periods. To keep pace here, prices and product lines have to be regularly adjusted by means of competitive comparison. Additionally, this creates the potential for higher margins and a better negotiating basis with suppliers.
And not least of all, a flawless and channel-independent management of product data is also decisive to customer experience: Erroneous orders and a migration to competitors would thus be eliminated.
This commentary from our foundress and CTO Dr. Hanna Köpcke has appeared in a similar form at BigData Insider.